
前言
要看懂这篇文章需要你对机器学习有基本的了解,至少了解 MLP 的原理,本文并不是零基础文章。
时序数据与模型
时序数据指的是一系列带有时序关系的数据,例如一段文本,先出现哪个字后出现哪个字是有时序关系的,字词顺序颠倒会导致意义不同,时序数据指的就是这一类数据点前后存在相关性的数据。
对时序数据的建模采用概率统计的方式进行,简单来说,我已经知道先前的一系列数据,模型能够得到下一个数据的概率分布,从而进行预测。
从数学上来说,这就是条件概率建模:
其中 就是针对时序数据的模型,此时我们可以根据前 t-1个样本,预测出第 t 个样本的值。如果引入自回归,即在预测出第 t 个样本之后,将这个样本当作已知的序列,那么现在就有前 t 个样本,就可以继续预测出第 t+1 个样本的值,这样形成一个自回归,可以预测多个时间步。
针对这一的概率模型,在传统方法上,有马尔可夫模型,这一方法假设当前的数据点只和前 n 个数据点相关,即进行时序数据的长度是确定的,就可以使用 MLP 等其他模型方法进行训练和建模,比较简单。
但这一的问题也显而易见,时序数据的相关性并不一定局限在一定的窗口内,有可能当前数据会影响到很久之后的数据分布,这一方法就无法捕捉这种关系。
如果想要处理不定长的时序数据,那么就可以使用隐变量模型,这一方法的概念是,对于每一个样本点,会根据当前样本点 和隐变量 ,计算出一个隐变量 来表示过去的信息提供给下一个样本点使用。
换句话说,隐变量是一个包含过去信息的特征向量,他是一个对过去信息进行汇总的变量,要计算出一个隐变量,则需要当前的隐变量和样本点。也可以理解为当前样本点对隐变量产生了某种影响,从而产生了一个新的隐变量,这一隐变量就被用来表示时序信息。
这时候我们就不再需要前 n 个样本点了,我们只需要第 n 个样本点和一个隐变量 就可以了。
在数学上隐变量 ,实际上就是另一种对时序数据建模的方式。
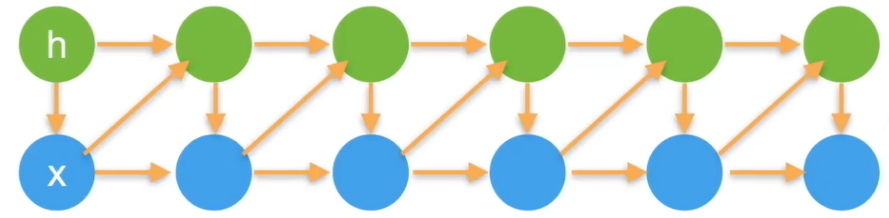
循环神经网络 RNN
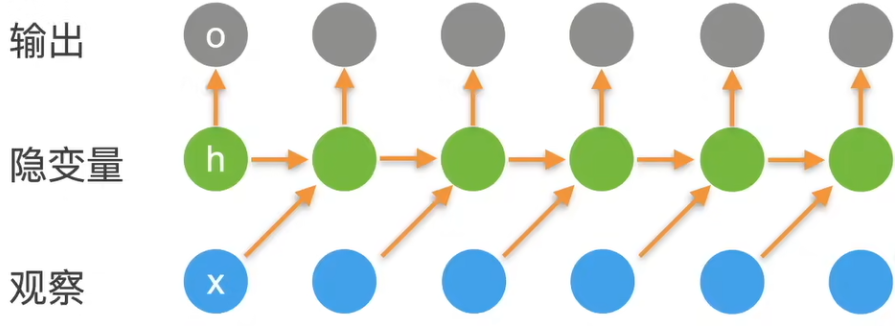
循环神经网络是隐变量模型的一种,对于给定的一个序列 ,其中有多个时间步 ,每个时间步都会和当前的隐变量进行计算,产生下一个隐变量,输出则是根据隐变量生成的,而非基于序列。
这里实际上就只涉及到两个计算,第一个是如何通过当前时间步的观察和隐变量生成下一个隐变量,第二个是如何通过隐变量生成输出。
假设隐变量为 ,当前时间步的数据为 ,计算隐变量的数学表达式为:
其中 为激活函数, 是用于隐变量生成隐变量的权重, 是用于观察值生成隐变量的权重,在这里结合的方式是通过加法, 是偏置项。
假设输出为 根据上式生成的隐变量 ,再给出计算输出的数学表达式:
其中 是用于隐变量生成输出的权重, 是偏置项。
所以对于一个 RNN,其要学习的权重向量总共就只有三个,不同时间步也是共享这一组权重。
需要注意的是,在起始时刻,是没有前一时刻的隐变量的,所以需要一个初始化的隐变量。
训练
考虑前向传播是基于当前隐变量和当前观察值生成下一个隐变量,在循环生成达到序列末端时算作是一次前向传播。
所以 RNN 的训练是对一个时间序列进行反向传播,每个时间步的输出和标签进行计算,计算整个序列之后得到一个累加的误差,然后进行反向传播更新权重值。在序列的反向传播过程中,可以认为每个时间步对权重的更新是在对时序特征进行抽取。
梯度裁剪
在反向传播计算梯度时,时间步较大的偏导计算会跨越多个时间步,形成多次偏导,这和深度神经网络的反向传播一样,如果没有一些措施,会导致梯度爆炸或梯度消失。这是因为多个时间步中梯度信号的积累,即多个矩阵相乘,其值会不稳定。
但是在这里只进行梯度裁剪,即设置一个梯度上限,当梯度大于上限时,设置为上限,不管梯度过小的情况。
RNN 的拟合能力
也许你会有疑问,RNN 一共就训练三个权重,怎么拟合复杂的数据?而且基于数学公式可以看出,RNN 和 MLP 相比只是多了一个隐变量的计算,如果去除掉隐变量,就退化成一个包含两个隐藏层的 MLP。我们知道两层的 MLP 是难以拟合复杂的数据的。
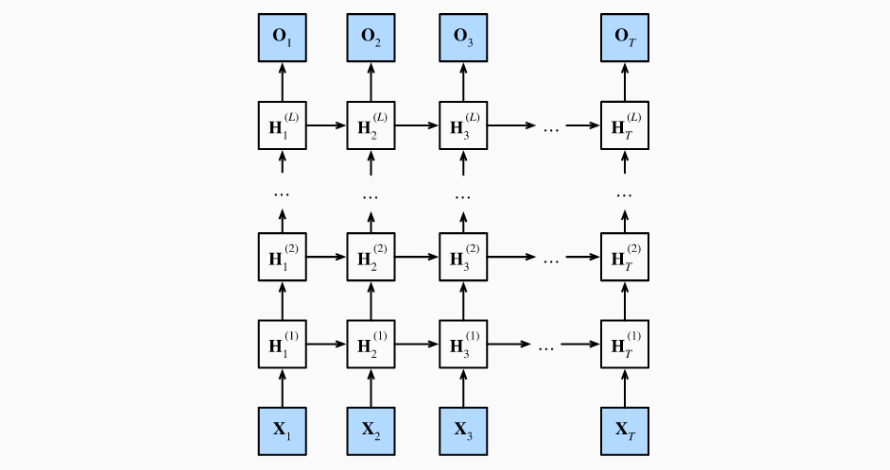
如果要拟合的数据比较复杂,我们也可以对 RNN 的深度进行加深。RNN 的加深维度是在隐变量到输出这一部分,我们可以将隐变量进行拓展,变成第一层的隐变量、第二层的隐变量等等。通过这样的方式加深 RNN,从而提高拟合能力。
隐变量的变多也意味着总体来说,隐变量可以表示更复杂的时序特征,不仅数据本身的拟合能力提高,对时序特征的抽取能力也会相应提高。