
什么是 Attention?
通常很多教程或教材会告诉你,Attention 就是一种注意力,它可以让你关注更应该关注的,而忽略那些不应该关注的,Attention 通常代表某种兴趣点或关联性,Attention 机制使得模型会更关注有关联性的特征。
但是这种表达非常抽象,即使是用了比喻的方法,仍然不好理解 Attention 到底是怎么用在机器学习里面的,到底是如何生效的。更让人困惑的是,其中的三个权重被解释为查询(query)、键(key)和值(value),就更让人难以理解 Attention 是如何工作的。
也许这些教程或教材假设了某种你应该知道的前置知识,但是至少从我的角度出发,我并不能很好的理解这些含义。
通俗地讲,Attention 是给模型一种选择权,Attention 会接收到一个输入,然后他要做的是找到那些和这个输入相关的那些信息(你也可以说是「注意到」或「兴趣点」,总之是一种相关性),并进行某些计算,最终得到一个输出。这个输出就是模型选择之后的结果,只考虑(计算)了那些相关的,而忽略那些不相关的信息。
那么 Attention 是如何找到那些相关信息的呢?这个就是 Attention 根据数据集学来的。那 Attention 要找的那些相关信息是什么?这里有多种方式,并不固定,可以是数据本身的信息,也可以是人为构造的一些相关信息让模型选择。
更形式化的理解
有了上述直观的理解,更形式化地讲:
- Attention 会收到一个输入 query,视作是一个查询
- 接着 Attention 在相关信息里找,哪些信息是和这个 query 相关的,视作是根据 query 在一堆 key 里面查询
- 找到这些信息之后,进行某种计算,得到一个输出,视作是根据 key 找到 value 之后,根据 value 进行某种计算
那么 Attention 是如何产生作用的呢?我们先假设将 Attention 应用在翻译任务上,翻译任务是一个典型的 Seq2Seq 的任务,假设你已经了解 Seq2Seq 和编码器-解码器结构。
假设我们要对一个句子进行翻译,将「你好吗?」翻译为「How are you?」
首先对于「你好,世界!」,我们会将该文本送入编码器进行编码,将每个词元编码后送入到 Attention 里面构造 key-value 对,这里文本我们让 key 和 value 相同。实际上词元在经过编码之后是某种中间向量表示,我们将该向量视为 key,然后构造 key-value 对放到 Attention 里面,以便之后可以进行查询。
但是我们可以认为 key 实际上就文字本身,只是换了一种表达形式。换句话通俗的说,我经过编码器之后,Attention 知道了,我现在的输入有这些东西,我把他们准备好,以便后续我查找一些我觉得相关的东西来帮助我更好地完成任务。
那 key 和 value 相同又是怎么回事?这里是因为文字就代表他本身,也就是说 Attention 说我知道了我的输入里面有一个文字(key),那他的含义(value)是什么?在这个任务中,文字的含义就是文字本身。
在其他任务中,你可以让 key 和 value 不一样,key 代表输入是什么,value 代表其含义是什么。例如对一段文本进行情感分类,我们构造 key-value 对时,就可以让 key 仍然是词元的向量表示,但是 value 可以设置为情感标签。这样就设计了一个词和情感的 key-value 对,模型可以更好地注意到词是积极的还是消极的,最终对整段文本进行情感分类。
那么 query 呢?
至此,我们根据输入构造了一系列的 key-value 对,当然也可以人为构造一些 key-value 对,这叫做 Hard-Attention,但是目前我们仍然回到让模型自己构造,也就是 Soft-Attention。
回到原来的流程,我们通过编码器处理输入,获得了一系列的 key-value 对,在这个具体的例子中,就是「你好吗?」的每一个字。
接下来我们就到了解码的步骤,就是将文本真正翻译为英文。回到基础的 Seq2Seq,如果没有 Attention,解码器就是拿到编码器最后的一个隐藏状态,然后开始进行自回归地预测。Attention 作为一个额外的信息被引入到解码工作中。
假设我们现在预测出了第一个词「How」,然后我们将「How」作为一个 query,去看看我们的记忆里面有没有什么相关信息可以找到,也许 Attention 会说,「How」和问句有关系,所以他觉得这个词和「好」和「吗」都挺有关系的,然后计算出一个 Attention 的结果。
接着我们拿到这个 Attention 结果和解码器输入做一个拼接,送入到下一个时间步进行预测,也就是给下一次预测加入了一些额外的信息。这就是 Attention 做的所有事了。
这里存在一个小小的问题,第一个词是怎么预测出来的?
通常在文本生成时,第一个词的输入是一种特殊词元「BOS」,代表句子的开始 Begin of sentence,此时的初始注意力信息可以是零值,也可以是其他一些东西。
从整个模型的角度再梳理一遍流程。
首先我们根据输入的文本,经过解码器,每个时间步都会生成一个隐藏状态,我们使用该隐藏状态作为 key-value 储存到 Attention 的记忆中。所以此前所说 key 代表每一个字不那么准确,准确来说 key 代表的是每一个字,和该字此前时序信息的汇总。
在对所有输入进行编码之后,会得到最终的隐藏状态和一堆 key-value 对。接着我们就进入解码状态,对于第一个时间步,我们输入的是特殊词元「BOS」,额外的 Attention 信息是初始 Attention 信息,输入的隐藏状态是解码器最终的隐藏状态。
然后我们得到第一个预测,此时我们将进行 Attention,将第一个预测的输出作为 query,在 Attention 中寻找相关的信息,然后作为额外的 Attention 信息送入到下一个时间步的计算中。在这样的自回归过程中进行不断地预测,直到预测出了特殊词元「EOS」代表句子结束 End of sentence。
Attention 如何 Attention?
这是最后一个关键问题,Attention 是如何知道 query 和哪些 key 相关的?这就是靠模型根据数据自己学习出来的了,具体来说,Attention 通常有三个权重矩阵:
- 代表查询的可学习参数,用于将想要查询的向量投影到 query 的空间
- 代表键的可学习参数,用于将想要储存的 key 投影到 key 空间
- 代表值得可学习参数,用于将想要储存的 value 投影到 value 空间
所以我们可以得到查询 ,键 ,值 ,其中 是解码器在时间步 的隐藏状态, 是编码器在时间步 的隐藏状态。也就是说,需要将隐藏状态经过某种线性变换,投影到模型容易表征或学习的空间里,再做 Attention 要做的那些事。
Attention 要做的实际上就是根据 query 找到那些相关的 key,然后相关性大的,其 value 的权重就高。在数学上,我们首先要计算 query 和 key 的相关性分数:,相关性高的,其值就大,否则其值就小,该值实际上就是权重了。
然后我们再对相关性分数做 softmax 进行归一化:
最后对 value 进行加权和,得到 Attention 的输出:
其中 代表编码器输入序列的长度,也就是有多少个 key-value 对,最终就得到我们的结果了。
(李宏毅网课的示意图,每一个输出 都充分考虑了所有输入 )
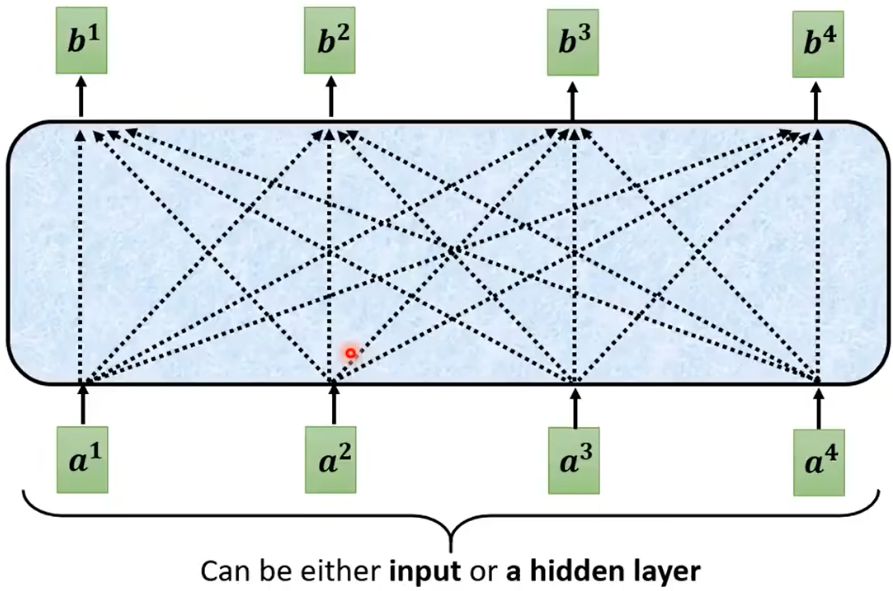
自注意力 self-attention
通常我们使用 Attention 是为了捕获输入数据本身之间的相关性,这种相关性可能是跨越比较长的距离的,导致 CNN 和 RNN 等其他模型不容易捕获。我们为了捕获这种相关性而使用 Attention,我们可以手动构造一些键值对,在有时候并不是必要的。
self-attention 说的是,qkv 是同一个东西,我只需要 Attention 关注输入数据本身,尝试找到输入数据之间的某种相关性,通常就是指时序特征了。
self-attention 通常用于编码器部分,我们会一次性给 self-attention 完整的输入,和之前 Attention 计算一样,并没有什么不同。
直观来讲,self-attention 做的就如同名字一样,它关注自身的数据,并尝试抽取出其中的相关性/时序特征,作为一个额外的信息编码到中间表示向量中。
多头注意力 multi-head attention
多头注意力尝试要解决的是复杂相关性的问题,例如一段数据的时序特征可能比较复杂,那么一个 Attention 可能只能表达出某一部分的时序特征,无法完整地表达。毕竟一个 Attention 的参数量有限,无法实现复杂的特征抽取。
所以我们就实现了多个 Attention,试图让每一个 Attention 都能表达某一种的时序特征,那么多个 Attention 相比单个就能抽取出更多的时序特征。
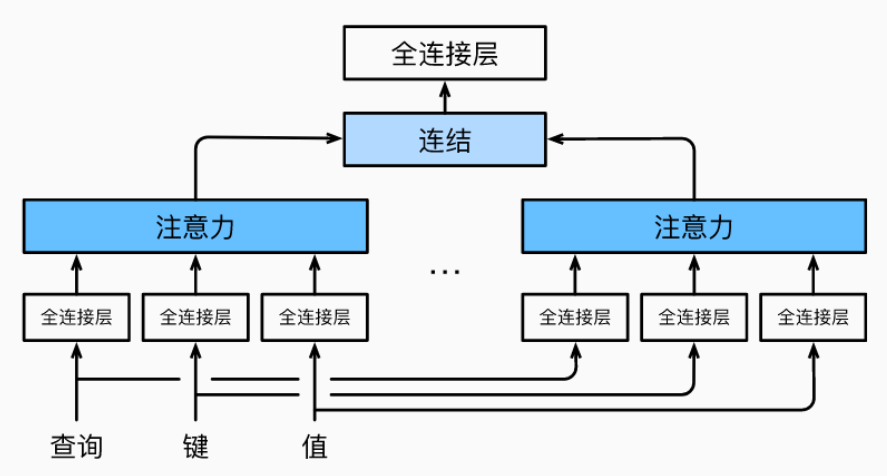
那么多头实际上就是并联了多个 Attention,并将最后的结果直接 concat 起来,在经过一个全连接层进行特征的融合或维度的变更。这样就能表达比简单加权和更复杂的函数,学习到数据中复杂的时序特征。
位置编码 Positional Encoding
学习完 Attention 的想法,你可能会发现一个问题,加权和只是对所有输入进行加权,输入与输入之间的顺序是不会影响加权和的结果的。所以如果输入数据发生顺序的变换,最终结果也是一样的,但这显然不是我们想要的,我们本身就希望 Attention 抽取出时序特征,那么时序关系变化应该要导致 Attention 结果的变化才行。
所以我们在数据中加入位置信息,当输入数据时序关系发生变化时,Attention 接收到的输入也会发生变化,以此来表示一种时序关系。
在位置编码中,我们做的就是计算一个位置编码 ,代表第 个位置数据的位置编码,然后把它的值加到输入上面就完了。
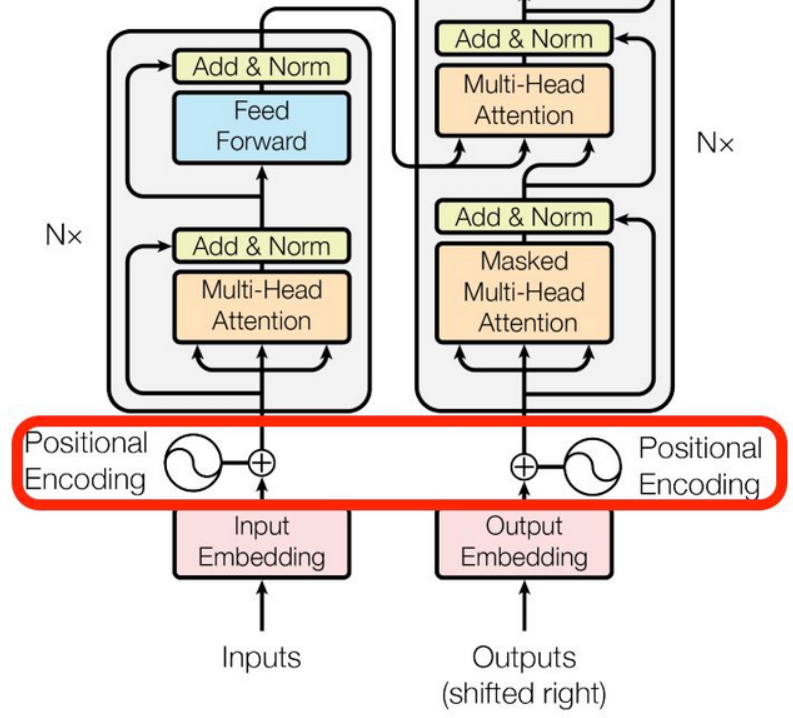
在 Transformer 架构里,就是做了一件这么简单的相加,而位置编码的计算方式并不统一,可以根据数据集的特点构造自己的编码方式。
具体来讲,在 self-attention 中,输入是没有时序信息的,对于任意一个时间步来说,其计算过程是完全一样的,没有因为其在序列后端或在时序前段而有所不同。
而在传统时序模型,例如 LSTM、RNN 这类循环结构的模型来说,其时序性是天然的。因为其计算流程是按照时序顺序来计算的,先计算第一个时间步,得到第一个时间步计算出来的隐变量之后,再计算第二个时间步。所以时序性是天然的,在计算过程中就自然带有时序性,这也导致了 LSTM、RNN 这类模型难以并行优化。
而 Transformer 提出就是为了加速计算,使其能够并行化,也就是输入的所有时间步可以同时计算,这就带来了并行加速的优化空间。但其就丢失了时序信息,所以我们需要再重新加入时序信息。
Positional Encoding 的思想是通过给每个时间步加上不同的影响,从而使模型能够自行学到其中时序性带来的影响。例如第一个时间步输入全部除以 2,第二个时间步全部乘以 3,希望模型能够学会时序性对输入带来的影响,从而学习到时序性。
在 Transformer 中,Positional Encoding 是通过 sin 和 cos 函数来实现相对位置的变化,具体来说,对于每一个时间步,都会根据 sin 和 cos 生成一个编码向量,然后直接加上原始的输入特征向量。
具体公式如下:
其中 代表时序数,例如输入序列的第三个时间步; 代表特征维度数,例如输入序列第三个时间步的第四个特征; 代表总的特征维度数,例如每个时间步的输入是 16 维特征的。其中的 10000 是一个人设的参数,一个大值可以让位置编码的周期更长,也就可以使更长的时间步有不同的变化,但太大又会使时间步之间的变化太小,所以也是一个可以调整的参数。 是加上位置编码之后的输入。
简单来说,对于每个时间步 ,其特征会受到不同程度的影响,从而使模型能够感知到时序性。