
前言
MapReduce 作为谷歌三剑客之一,在分布式系统领域有非常重要的作用,他带来 Map-Reduce 的分布式任务处理框架推动了分布式系统的发展。
对于 MapReduce,其可以简单概括为两个步骤,第一个是 Map,第二个是 Reduce。Map 的操作在于把原始巨大的任务打碎拆散,方便多个计算机领取自己的任务并计算出一些中间结果,Reduce 的操作就是收集这些中间结果,并给出最后的结果。
用比喻来说的话,为了制作一盘菜,对于多种原料,例如肉、菜、洋葱、辣椒等等,Map 的操作就是诸如腌制肉、切菜、切洋葱、切辣椒,每个 Map 任务相当于学徒,负责把原材料处理成中间状态。而 Reduce 相当于主厨,在拿到处理好的原材料之后,把他们做成一道菜。
有了 Map 和 Reduce 的直观理解之后,我们就可以开始学习 MapReduce 是如何在一个分布式系统中部署的了。
什么样的任务可以用 MapReduce 框架拆解?
在有关 MapReduce 的文章中,最经常举的例子是单词数统计。假设存在 1T 的文本文件需要统计单词数,显然一台计算机难以将 1T 的数据读入内存或这样做太慢。所以我们可以把文本文件进行拆分,例如一台计算机负责 100M 文件的词频统计。
于是每个节点(计算机),都可以得到一个词频统计的结果,通常用若干 key-value 对来表示。key 代表单词,value 代表出现频率。
这样在所有 Map 操作完成后,会有多个 Map 产生的中间 key-value 对,例如节点一产生:
hello: 2
to: 7
hello: 3
happy: 1
to: 7
happy: 2
节点二产生:
to: 3
to: 4
you: 2
get: 5
happy: 1
所有 Map 节点产生的 key-value 对最后会交给 Reduce 节点,Reduce 节点负责将这些结果进行最后的合并和统计。具体来说,每个 Reduce 任务会收到一组 key 相同的多个 key-value 对,然后对这个结果进行整合。例如 Reduce 节点一:
happy: 2
happy: 1
happy: 1
-> Reduce ->
happy: 4
最终多个 Reduce 节点进行合并,就可以得到最终结果:
you: 2
happy: 4
get: 5
hello: 5
to: 21
抽象一下这个过程,可以用以下符号表示:
下标 代表的是域,简单来说就是 Map 任务输入的 key-value 可能是「文件名-文件内容」,该键值对属于输入域,产生的是一个「单词-统计量」的列表,该键值对属于输出域,两个域表达的含义是不同的。然后 Reduce 任务对这些「单词-统计量」的列表进行整合,产生一个最后的值,代表某一个单词的总出现次数。
词频统计是一个很简单的任务,有没有更复杂一点的呢?
Reduce 在某些任务中可以不作任何事,Map 任务已经达到目标了
还可以有以下的任务:
- 分布式 Grep:Map 任务是对每一行进行字符串模式匹配,如果匹配则输出改行,Reduce 只需要输出中间结果即可
- URL 访问计数:Map 任务对多个日志进行统计,输出
<URL, count>,Reduce 函数将相同 URL 的访问次数加起来,输出<URL, total count> - 网页逆向链接图:Map 任务输入
<source, target>表示有一个网页链接从 source 到 target,并输出<target, source>,Reduce 任务收集所有 key 为 target 的值,然后输出<target, total source>
MapReduce 设计前提
MapReduce 可以有多种设计方式,考虑接下来的各种实现细节,必须了解其背后的前提,否则很难理解为什么这样设计。
- 单台机器的速度并不快(所以需要分布式发挥多台机器的性能)
- 单条的网络链路并不快(所以需要分布式发挥多链路的带宽优势)
- 集群又成百上千台机器组成,在这个尺度下机器故障几乎是必然(所以需要容错)
- 存储设备是常用的硬盘,没有严格的可靠性保证(文件需要有备份,这一点靠 GFS 实现)
流程概览
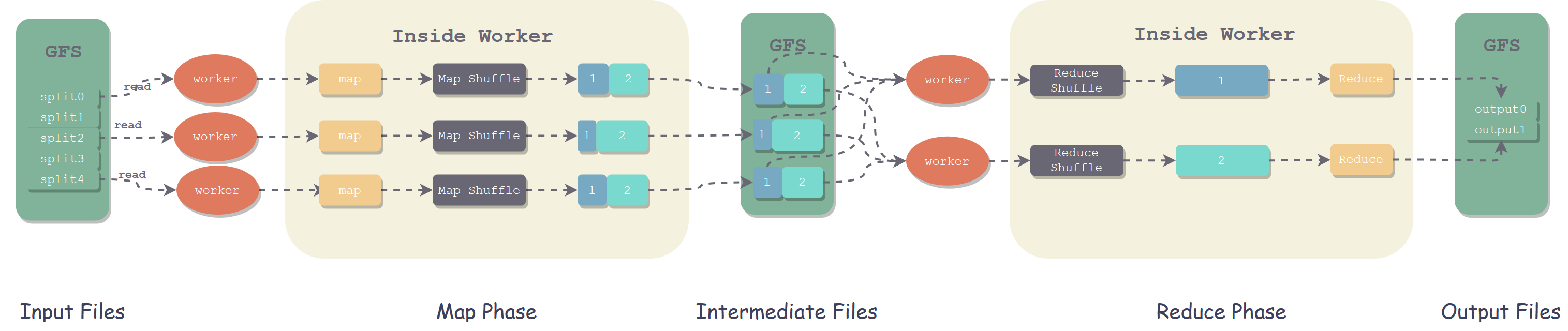
对于 MapReduce 框架,存在一个 Master 节点和其余 Worker 节点,Worker 节点可以是 Map 节点也可以是 Reduce 节点。
当一个计算需求上传到 Master 时,Master 会为 Worker 节点分配任务,共有 M 个 map task 和 R 个 reduce task 要分配,Master 选择空闲的 Worker 节点,分配一种 task。
被分配了 map task 的 Worker 读取响应的输入,并解析出 key-value 对的集合,如 Map 操作中所述。当 map task 完成之后,会通知 Master,Master 会收集这些 map task 的元信息进行管理。
随后 Master 会分配 reduce task,并告知其 map 之后的中间结果在哪个节点上,Reduce 节点会自行去取数据并计算结果。
最终完成之后,Master 唤醒用户程序,用户程序从 MapReduce 系统中获取最终结果。
Map 操作
此前简单概述了 Map 和 Reduce 在干嘛,在具体实践中,为了保证负载均衡,其操作会更复杂一些。
Map Shuffle
可以考虑一个简单的场景:词频统计,在 Map 之后得到了以下中间数据:
a: 1
b: 1
a: 1
c: 1
a: 1
b: 1
c: 1
对于 Reduce 节点来说,要去杂乱的 key-value 对中找自己需要的,显然非常浪费时间,因为列表是无序的。为了在这一步节省时间,我们需要保持中间数据的有序,这样检索起来可以快很多,例如有序排列成:
a: 1
a: 1
a: 1
b: 1
b: 1
c: 1
c: 1
在此基础上还可以加上索引,每一个 key 对应的一个数据范围,这样 Reduce 节点就可以根据索引直接获取数据,而不用一个个查找了。
这一步骤称为 Map 端的 Shuffle。在 Shuffle 完之后,我们需要将 Map 端的文件映射到 Reduce 节点,相同的 key 映射到同一个 Reduce 节点,让 Reduce 节点只会处理同一个 key 的数据,这就是接下来的 Paritition 工作。
Map Partition
为了使相同的 key 映射到同一个 Reduce 节点,并且多个 key 值的数据可以均匀地分布在多个 Reduce 节点上,我们再加上一个 partition 属性,基于 key 值计算 hash,将相同的 key 分区到同一个 Reduce 节点中:partition = hash(key) % numberOfReducers
需要注意的是,一种 key 值只会交给一个 Reduce 节点,但一个 Reduce 节点是可以处理多个 key 值地数据的。
这里你也许会产生这样的问题,假设一个 key 的数据占了 90%,其他 key 占了剩下的 10%,那么显然如果一个 Reduce 节点负责这全部 90% 相同的 key 会导致严重的性能瓶颈。但是实际上这说明了 key 值设计的不合理,在 key-value 键值对设计时就应该保证 key 值分布均匀。
具体来讲,每个 Map 节点会根据一部分的数据生成一部分的键值对,并保证这部分的键值对是有序的,所以会将一部分的有序键值对传给 Reduce 节点(根据 Partition 决定传给哪个)。在 Reduce 节点收到这么多小的有序的集合时,会先进行一次全局的合并操作,合并成一个总的、大的有序集合,随后进行 Reduce 任务。
Map Collector
Shuffle 的介绍是从一个宏观的角度,Collector 则是其具体实现的承载者。在产生了最终输出之后,Collector 机制会将最终的结果写入磁盘中,以方便 Reduce 节点从中获取数据。
首先 Collector 会将数据存储在内存中,这被视为是一个高速缓冲区,但是内存的容量有限,当达到一个触发阈值之后,内存中的数据会写入磁盘,这一过程叫做 Spill。
在 Spill 触发后,Collector 首先会根据 partition 和 key 对数据进行排序。按照 partition 排序,可以让同一个节点的数据聚合在一起,方便 Reduce 节点获取数据;在 partition 内部再根据 key 值对数据进行排序,使相同的 key 值聚合在一起,方便 Reduce 处理数据。
最终 Collector 会创建磁盘文件,将数据写入磁盘中,同时创建一系列的索引文件,方便 Reduce 节点获取数据。
在数据量较大时,可能会产生多次 Spill,这样就需要将多次 Spill 产生的文件进行合并,这一过程设计到外部排序。
Reduce 操作
Reduce 节点的操作则简单得多,对于 Map 完成之后的数据,Reduce 节点会对每个 key 下的所有值进行计算,例如求和、平均等等计算。最终将会产生一个输出文件,文件名通常与 Reduce 的任务编号相关。
容错机制
文件系统容错
在文件系统容错这部分,由其底层的分布式文件系统来保证,例如 GFS、HDFS 等,每个文件块会有多个副本分布在不同的物理机器上,本文不再赘述。
需要注意的是,Map 节点、Reduce 节点、文件块所属节点有可能在同一个物理机器上,并不一定严格区分哪些物理机器是某些节点。
Map 任务容错
对于一个 MapReduce 框架,存在一个 Master 节点来调控全局,Master 节点和 Map 节点之间有定期的心跳检测,如果心跳没有及时回复则认为该节点宕机,将会进行任务的再分配。
Master 管理的 Map 任务存在三种状态:
- 未分配
- 执行中
- 执行成功
当 Master 与一个 Map 节点失联,其所分配的 map task 会被标记为未分配,随后重新加入任务调度中进行任务的再分配。
假如此时该 map task 已经执行成功了,也仍然需要重新计算,因为该 map task 的结果储存在该节点上,而该节点已经失联,其结果已经不可获取,仍然需要重新计算。所以此时还要额外通知 Reduce 节点,让他去再分配的这个节点获取 map task 的结果。
Reduce 任务容错
Reduce 任务同样具有三种状态,对于执行中的 reduce task,会被再分配,如 Map 任务容错中一样。但对于已经完成的 reduce task,则不需要再分配,因为 reduce task 完成后会输出到全局的一个文件系统中,而不是储存在该节点的本地磁盘中。
Master 失败
Master 执行周期性地 checkpoint 保存,如果 Master 宕机,可以很容易地从 checkpoint 恢复,而不需要重新执行一遍完整的任务。
原子性保证
每个 task 会将输出写入到私有的 temp 文件中,一个 reduce task 会产生一个 temp 文件,一个 map task 会产生多个 temp 文件。
当一个 map task 完成后,会像 Master 发送所有 temp 文件名称的信息,如果 Matser 已经收到过一次该 map task 的完成信息,则会忽略,否则就记录到自己的数据结构中。这样就保证了对于同一个 map task,只有一个结果。(每个 map task 都会有其任务 id,根据该 id 进行管理)
当一个 reduce task 完成后,Reduce 节点会自动把 temp 输出文件重命名为最终的输出文件(输出文件储存在全局文件系统中)。对于一个相同的 reduce task,多个重命名操作将会在同一个最终输出文件时执行,也就是说输出会覆盖原有的文件,来保证了对于一个 reduce task 只会有一个结果文件。(重命名覆盖由底层文件系统来保证原子性)
进程 Crash
对于 map task 或 reduce task,有可能其代码本身就存在 bug,导致在某个计算中产生进程崩溃。Worker 节点会捕捉这些崩溃信号,并将发生崩溃的位置发送给 Master 节点,当 Master 节点在同一记录上收到多次失败反馈后,在重新分配任务时,则会跳过这些记录。
这样的操作是可选的,视具体任务情况而定。
性能优化
局部性
本地的数据传输显然远快于网络数据传输,为了提高性能,Master 会尽可能让 map task 调度到存储所需数据的那台物理机器上,如果不可行,则尽可能使 map task 在数据附近,使得大部分的数据是从本地获取的,而不用占用网络带宽。这对于 reduce task 的分配也是类似的。
任务备份
当某一个 map task 或 reduce task 执行极慢,例如硬盘性能下降,机器设备资源耗尽等等问题。导致这些任务的执行异常缓慢,拖慢了整个任务的执行速度,其他大部分执行完了,但还需要等待这一小部分的结果,产生瓶颈。
当 MapReduce 操作接近结束时,Master 会备份目前还在执行的 task,让多台机器执行同一个 task,只要其中一个副本完成,就认为其完成了。通过这种机制,可以通过仅仅增加几个百分点的性能损耗下大大提高总体的执行速度。
局部 Reduce
对于一些特定的任务,可以在 map task 中执行一部分的 reduce 操作,例如:
a: 1
a: 1
a: 1
b: 1
b: 1
c: 1
c: 1
可以提前 reduce 简化为:
a: 2
a: 1
b: 2
c: 1
c: 1
减少了后续 reduce task 所需的计算量。