
前言
该系列是《C++Primer第五版》的笔记,包含本人认为值得记录和整理的主要的知识点,并不是全部内容,也不是具体的内容。
该系列文章的作用应该是作为复习或预习的参考,有哪些知识点忘记或想学,可以大致浏览下该文章,然后再去书中寻找详细解答。(本系列文章基本是按书本顺序罗列的知识点,便于大家去书中寻找)
所以看该文章前,需要有一定的C++基础,否则阅读起来可能有困难。
本文大致整理了第十八章的知识点,涉及到C++关于异常、命名空间和多重继承的知识。
链接目录
- 第二章:变量与基本类型
- 第三章:字符串、向量和数组
- 第四章:表达式
- 第五章:语句
- 第六章:函数
- 第七章:类
- 第八章:IO库
- 第九章:顺序容器
- 第十章:泛型算法
- 第十一章:关联容器
- 第十二章:动态内存
- 第十三章:拷贝控制
- 第十四章:重载运算与类型转换
- 第十五章:面向对象程序设计
- 第十六章:模板与泛型编程
- 第十七章:标准库特殊设施
- 第十八章:用于大型程序的工具
- 第十九章:特殊工具与技术
抛出异常
当执行一个throw时,跟在throw后面的语句不会执行,程序控制权移交给catch块,此时:
- 沿着调用链的函数可能会提早退出
- 一旦程序开始执行异常处理代码,沿着调用链创建的对象将会被销毁
栈展开:抛出一个异常后,程序暂停执行,开始寻找匹配的catch块,该过程可能会不断沿着函数调用链不断退回,直到找到匹配的catch块。
当找不到匹配的catch块,程序将调用标准库函数terminate,终止程序。
异常可能发生在构造函数中,当前对象可能指构造了一部分,应该保证某个对象即使只构造了一部分也能正确的被销毁。
析构函数与异常:析构函数总是会被执行,但是函数中释放资源的代码可能不会被执行。因此用类来控制资源的分配,就能保证函数是正常结束还是遭遇异常都能正确释放。
析构函数不应该抛出不能被自身处理的异常,即析构函数抛出的异常,在本函数内就能得到解决。一旦栈展开过程中析构函数抛出异常,并且析构函数自身没能捕获,程序会被终止。
throw语句中的表达式必须具有完全类型。
捕获异常
catch子句中的异常声明必须是完全类型,可以是左值引用,但不能是右值引用。
catch的匹配并不一定是异常的最佳匹配,异常只会匹配第一个匹配的catch块。与实参和形参的匹配规则相比,异常和catch异常声明的匹配严格得多:
- 允许从非常量向常量转换
- 允许从派生类向基类的类型转换
- 数组被转换成数组类型的指针,函数被转换成指向该函数类型的指针
除此之外,包括算术类型转换和类类型转换都不能在匹配catch过程中使用。
如果多个catch语句的类型之间存在继承关系,则应该把继承链最底端的类放在前面,最顶端的类放在后面。
重新抛出:一条catch语句通过重新抛出将异常传递给另一个catch语句,但是这里不包含任何表达式,只有throw;
捕获所有异常的处理代码:catch(...)会与任意类型的异常匹配。catch(...)通常放在最后面,如果放在前面,则后面的catch将永远不会匹配。
void manip(){
try{
...
}
//catch-all通常和重新抛出一起使用
catch(...){
throw;
}
}
函数try语句块与构造函数
针对构造函数初始值异常的方法,由于初始值列表并不在函数体中,所以采用这种特殊的try方式处理构造函数初始值列表的异常。
//在此构造函数中的初始化可能产生异常
Blob::Blob(initializer_list<MyClass> il)
try : data(make_shared<vector<MyClass>>(il)){}
catch (const bad_alloc &e) {...}
noexcept异常说明
说明该函数不会抛出异常,但该函数内仍然可以抛出异常,此时抛出异常会终止程序,不会进行异常处理。
所以noexcept用作两种情况下:
- 确认函数不会抛出异常
- 根本不知道如何处理异常
异常说明与指针、虚函数和拷贝控制:
- 某个函数指针做了不抛出异常的声明,则该指针只能指向不抛出异常的函数。普通函数指针既可以指向不抛出异常的函数,也可以指向可能抛出异常的函数。
- 一个虚函数声明不会抛出异常,则派生的虚函数也必须声明不会抛出异常。如果虚函数没有声明不会抛出异常,则派生的函数既可以抛出异常,也可以不抛出。
- 如果对所有成员和基类的所有操作都承诺不会抛出异常,则合成的拷贝控制成员也是
noexcept的。
异常类层次
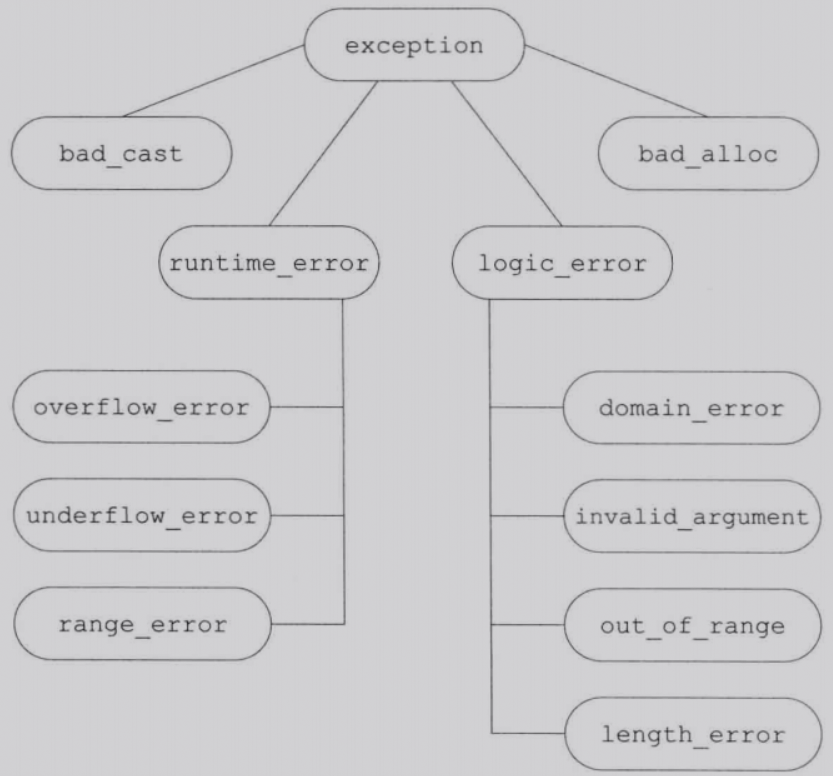
exception类定义了拷贝构造函数、拷贝赋值运算符、一个虚析构函数和一个what的虚成员,what返回一个const char*,一个以unll结尾的字符数组。
命名空间
多个库中的某些名字相互冲突,如果都放在全局命名空间中会引发命名空间污染。
命名空间定义
//在命名空间cplus_primer中定义了一个名为Sales_data的类
//打开命名空间cplus_primer
namespace cplus_primer{
class Sales_data{/* */};
...
}
//通过作用域运算符::来使用
cplus_primer::Sales_data val = cplus_primer::Sales_data(...);
命名空间可以是不连续的,定义一个命名空间,如果已经存在同名的命名空间,则会添加新成员,否则新创建一个新命名空间。
#include应该出现在打开命名空间的操作之前,否则会出现命名空间的嵌套,可能导致错误。
嵌套的命名空间:
namespace cplus_primer{
namespace QueryLib{
...
}
namespace Bookstore{
...
}
}
//嵌套访问
cplus_primer::QueryLib::Query
内联命名空间:外层命名空间可以直接使用,不用再额外添加::去访问。
使用命名空间成员
命名空间的别名:
namespace Qlib = cplus_primer::QueryLib;
using指示:using namespace ..可以出现在全局作用域、局部作用域和命名空间作用域中,但不能出现中在类的作用域中。
using指示一次性注入某个命名空间的所有名字,如果在头文件的顶层作用域使用,可能会导致命名空间污染的问题,所以头文件最多只能在函数或命名空间内使用using指示。但如果是命名空间本身的实现文件,那使用using指示就没问题。
类、命名空间与作用域
名字的查找从内层向外层向上查找,即名字在使用前必须先声明。
实参相关的查找与类类型形参,当给函数传递一个类类型对象时,除了在常规的作用域查找外,还会自动查找实参类所属的命名空间,此时就不需要额外进行命名空间的声明。
//例如 operator>>(std::cin, s);
//可以直接使用,而不用声明 using std::operator>>;
std::cin >> s;
友元声明与实参相关的查找:
namespace A{
class C{
friend void f2();
friend void f(const C&);
};
}
int main(){
A::C cobj;
f(cobj);//正确,会自动查找类所属的命名空间
f2();//错误,没有参数不会自动查找,必须使用A::f2
}
重载与命名空间
与实参相关的查找和重载:传递给display的实参属于类类型,所以会在类类型所属的作用域中查找,包括Bulk_item继承的基类Quote。
namespace NS{
class Quote{...};
void display(const Quote&){...}
}
class Bulk_item : public NS::Quote{...};
int main(){
Bulk_item book;
display(book);
return 0;
}
重载和using声明:using声明只是名字的别名,和名字一样,内层作用域的同名会隐藏外层作用域的名字,同层作用域如果有同名函数,会进行重载。
using NS::print(int);//错误,不能指定形参列表
using NS::print;//正确,该函数的所有版本都会引入作用域
重载与using指示:与using声明不同,using指示引入一个参数列表和名字完全相同的函数也不会出错,但是此时需要指明调用的是哪个版本。
多重继承
每个基类包含可选的访问说明符,class默认说明符是private,struct默认是public
Panda类中基类的构造函数是按声明顺序一致的,如Panda中基类的构造顺序是Bear、Endangered,析构函数则相反,~Panda、~Endangered、~Bear。
class Panda : public Bear, public Endangered{
};
类型转换与多个基类
多个基类的指针都可以指向派生类对象,且编译器无法判断派生类向几种基类的转换的优劣。和单继承一样,某个基类的指针只能使用某基类的成员,无法使用其他基类或派生类的成员。
void print(const Bear&);
void print(const Endangered&);
Panda pd();
print(pd);//二义性错误,无法选择调用哪个版本
多重继承下的类作用域
多重继承查找名字仍然是自底向上,如果一个名字在多个基类中出现,会出现二义性,在使用时必须指出使用的是哪个类作用域中的名字,即使成员函数参数列表不同也会报错。
虚继承
例如B、C继承了A,D继承了B和C,那么D中就间接继承了A两次,会有A的两份拷贝。如果我们只需要一份A对象,就需要用到虚继承,共享的基类子对象称为虚基类,该对象不管在继承体系中出现了多少次都只会有一个对象实例。
使用虚基类:通过关键字virtual
class A{};
class B : public virtual A{};
class C : public virtual C{};
class D : public B, public C{};//只会存在一份A的实例对象
虚继承并不影响用基类的指针指向派生类的对象。
关于虚基类的同名成员:例如类B定义了x成员,D1和D2虚继承B,D继承D1和D2
- 如果
D1和D2都没有x的定义,x会被解析为B的成员 - 如果
D1和D2某一个中有x的定义,则解析为D1或D2的成员 - 如果
D1和D2都有x的定义,则直接访问会产生二义性
构造函数与虚继承
虚继承的对象的构造方式:首先使用最低层派生类构造函数的初始值初始化该对象的虚基类部分,让然后按照直接基类在派生列表中的次序进行初始化。虚基类总是先构造的,与继承体系中的次序和位置无关。
构造函数与析构函数的次序:一个类如果有多个虚基类,那么构造顺序仍然按照派生列表中出现的顺序构造。合成的拷贝控制成员按照完全相同的顺序执行,析构函数则相反。