
前言
该系列是《C++Primer第五版》的笔记,包含本人认为值得记录和整理的主要的知识点,并不是全部内容,也不是具体的内容。
该系列文章的作用应该是作为复习或预习的参考,有哪些知识点忘记或想学,可以大致浏览下该文章,然后再去书中寻找详细解答。(本系列文章基本是按书本顺序罗列的知识点,便于大家去书中寻找)
所以看该文章前,需要有一定的C++基础,否则阅读起来可能有困难。
本文大致整理了第十一章的知识点,涉及到C++关于关联容器的知识,属于STL中比较基础的部分,在日常算法中也经常用到,重点掌握。
链接目录
- 第二章:变量与基本类型
- 第三章:字符串、向量和数组
- 第四章:表达式
- 第五章:语句
- 第六章:函数
- 第七章:类
- 第八章:IO库
- 第九章:顺序容器
- 第十章:泛型算法
- 第十一章:关联容器
- 第十二章:动态内存
- 第十三章:拷贝控制
- 第十四章:重载运算与类型转换
- 第十五章:面向对象程序设计
- 第十六章:模板与泛型编程
- 第十七章:标准库特殊设施
- 第十八章:用于大型程序的工具
- 第十九章:特殊工具与技术
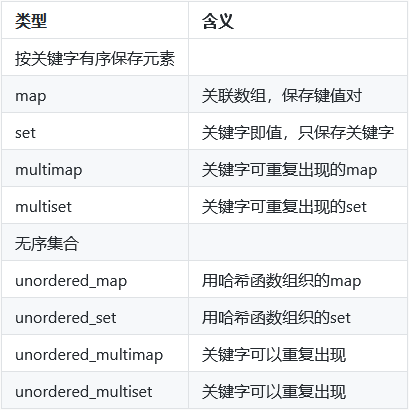
使用关联容器
关联容器支持高效的关键字查找和访问:
map:元素是一些键值对(key-value),关键字起索引作用。set:每个元素只包含一个关键字,支持高效的关键词查询操作。
标准库提供8个关联容器,map和multimap定义在头文件map中;set和multiset定义在头文件set中;无序容器则定义在头文件unordered_map和unordered_set中。
使用map:
//统计每个单词出现的次数
map<string, size_t> word_count;
string word;
while(cin >> word)
++word_count[word];//如果word不在map中,会创建一个新元素
//map中的元素是pair类型的对象,保存两个成员first和second
for(const auto &w : word_count)
cout << w.first << " " << w.second << endl;
使用set:
set<string> exclude = {"The", "But", "And"};
//find返回一个迭代器,如果有关键字word,则指向该关键字,否则返回尾后迭代器
if(exclude.find(word) == exclude.end())
//do something
定义关联容器
定义map必须指明关键字类型和值类型,定义set只需指明关键字类型。
关键字类型的要求
对于有序容器:map、multimap、set和multiset来说,关键字类型必须定义元素比较的方法。默认情况下,标准库使用<运算符来比较。
有序容器的关键字类型:可以提供自定义的操作来代替<运算符。所提供的操作必须定义一个严格弱序(小于)。
比较函数必须具备以下性质:
- 两个关键字不能同时小于对方,如果
k1小于k2,那么k2不能小于k1。 - 如果
k1小于k2,且k2小于k3,那么k1必须小于k3。 - 如果存在两个关键字,任何一个都不小于另一个,那么就是等价的。如果
k1等价于k2,且k2等价于k3,则k1等价于k3。
例如只用一个严格弱序就能表示元素的三种关系:
//a小于b
a < b
//b小于a
b < a
//a等于b
!(a<b) && !(b<a)
如果两个关键字是等价的,那么容器将它们视为相等来处理。
使用关键字类型(自定义)的比较函数:第一个参数为set的值类型,第二个参数为比较函数的函数指针。
bool compare(const string &s1, const string &s2){
return s1.size() < s2.size();
}
multiset<string, decltype(compare)*> arr(compare);
pair类型
pair是标准库类型,定义在头文件utility中,数据成员first和second是public的。
pair<string, string> anon;
//提供初始化器
pair<string, string> author{"James", "Joyce"};

创建pair对象的函数:
pair<string, int> f(){
...
return pair<string, int>();
//也可以用make_pair
return make_pair(s, i);
}
关联容器相关数据类型

关联容器迭代器
auto map_it = word_count.begin();
cout << map_it->first;
map_it->first = "new key";//错误,first是const的
set的迭代器是const的:可以访问元素值,但不能修改。
遍历关联容器:map和set都支持begin和end操作。
auto map_it = word_count.cbegin();
while(map_it != word_count.cend()){
cout << map_it->second << endl;
++map_it;//递增迭代器,移动到下一个元素
}
关联容器和泛型算法:通常不对关联容器使用泛型算法,关联容器的元素在内存中并不一定是连续的,所以尽量使用关联容器本身就带有的算法,而不是使用泛型算法。
添加元素
向map添加元素:map中元素是pair,需要构造一个pair对象。
word_count.insert({word, 1});
word_count.insert(make_pair(word, 1));
word_count.insert(pair<string, size_t>(word, 1));
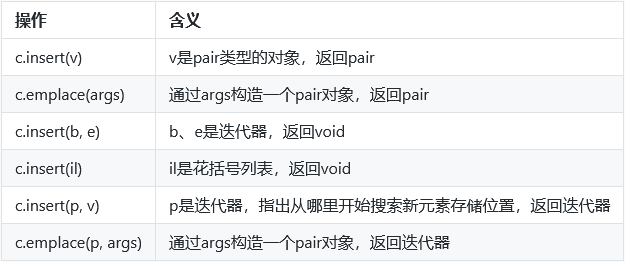
检测insert的返回值:insert的返回值依赖于容器类型和参数。
- 对于不包含重复关键字的容器,返回一个
pair,first成员是一个迭代器,指向插入的元素,second是一个bool值,如果关键字不存在,bool为true,如果存在则不进行插入操作,返回false。
展开递增语句:
while(cin >> word){
auto ret = word_count.insert({word, 1});
if(!ret.second)
++ret.first->second;//递增计数器,对关键字出现次数进行计数
}
//等价于++((ret.first)->second);
向multiset和multimap添加元素:调用insert总会插入一个元素,返回一个指向新元素的迭代器。
删除元素
关联容器有三个版本的erase:
- 参数:一个迭代器,返回
void。 - 参数:一对迭代器,返回
void。 - 参数:
key_type类型,删除所有匹配给定关键字的元素,返回删除元素的数量。
map的下标操作
map和unordered_map容器提供了下标运算符和一个对应的at函数,set不支持下标操作。不能对multimap或unordered_multimap进行下标操作,因为这些容器可能有多个值与一个关键字相关联。
与其他下标运算符不同,如果关键字不在map中,会创建一个插入到map中,并对关联值进行值初始化。
操作:
c[k]:返回关键字为k的元素,若不在c中,插入值c.at(k):访问关键字为k的元素,若不在c中,抛出异常
使用下标操作的返回值:解引用迭代器所返回的类型与下标运算符返回的类型是一样的,但对map则不然。
- 对
map进行下标操作,返回mapped_type对象。 - 对
map的迭代器进解引用操作,返回value_type对象。
访问元素
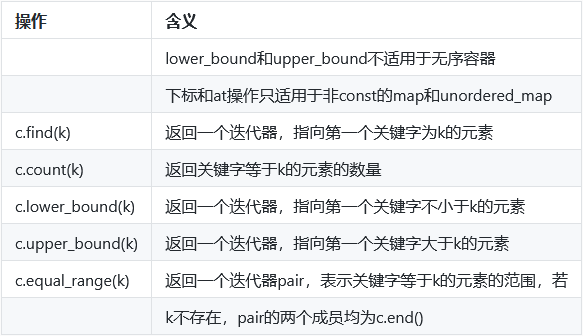
对map使用find代替下标操作:由于当元素不存在时执行下标操作会插入一个元素,所以在这种情况下,应该以find代替下标。
在multimap或multiset中查找元素:重复的关键字储存在容器中的相邻位置。
string s("The");
auto entries = authors.count(s);//元素的数量
auto iter = authors.find(s);//s的第一个位置
while(entries){
cout << iter->second << endl;
++itere;
--entries;
}
面向迭代器的解决方案:lower_bound和upper_bound,如果没有给定的元素,则lower_bound和upper_bound返回相同的迭代器(可以进行插入的位置)。
for(auto beg = authors.lower_bound(s), end = authors.upper_bound(s);
beg != end; ++beg)
cout << beg->second << endl;
使用equal_range函数访问:接受一个关键字,返回一个迭代器pair。
- 如果关键字存在,第一个迭代器指向第一个匹配的位置,第二个迭代器指向最后一个匹配位置之后的位置。
- 如果不匹配,则两个迭代器都指向可以进行插入的位置。
for(auto pos = authors.equal_range(s);
pos.first != pos.second;++pos.first)
cout << pos.first->second << endl;
无序容器
新标准定义了4个无序关联容器,它们不用比较运算符来组织元素,而是使用哈希函数和==运算符。
使用无序容器:无序容器也提供了和有序容器相同的操作,但由于存储方式不同,有些操作的结果可能不同。
管理桶:无序容器在存储上组织为一组桶,每组桶保存零个或多个元素,通过哈希函数映射。
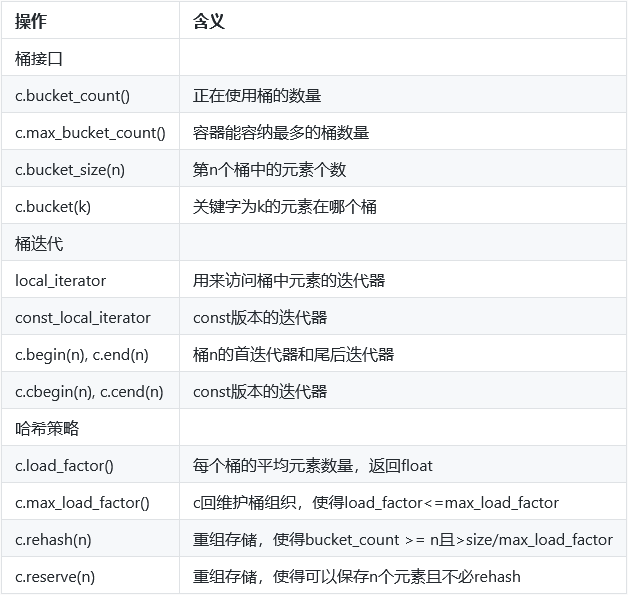
无序容器对关键字类型的要求:默认情况下使用关键字类型的==运算符来比较元素,它们还使用一个hash<key_type>类型的对象来生成哈希值,标准库为内置类型提供了hash模板,但自定义类型没有,所以如果使用自定义类型为关键字,则需要自定义hash模板。
size_t hasher(const Sales_data &sd){
return hash<string>()(sd.isbn());
}
bool eqOp(const Sales_data &e1, const Sales_data &e2){
return e1.isbn() == e2.isbn();
}
//参数是桶大小、哈希函数指针和相等性判断指针
unordered_multiset<Sales_data, decltype(hasher)*, decltype(eqOp)*> bookStore(42, hasher, eqOp);
//过长的定义可以使用using
using SD_multiset = unordered_multiset<Sales_data, decltype(hasher)*, decltype(eqOp)*>;
SD_multiset bookStore(42, hasher, eqOp);