
前言
为了实现强大的 debug 信息,例如变量类型、变量信息、自动打印容器内元素等等功能,这部分需要获取到编译信息,正常手段应该很难获取到,要借助编译器,就只能利用模板元编程和宏来实现。所以该库的核心就是 宏 和 模板元编程 。
所以阅读源码需要你对宏和模板元编程有一定了解,特别是 type_traits,以下分析均对源码做了简化,只分析其核心的原理部分,具体实现还需阅读源码。
UML 图
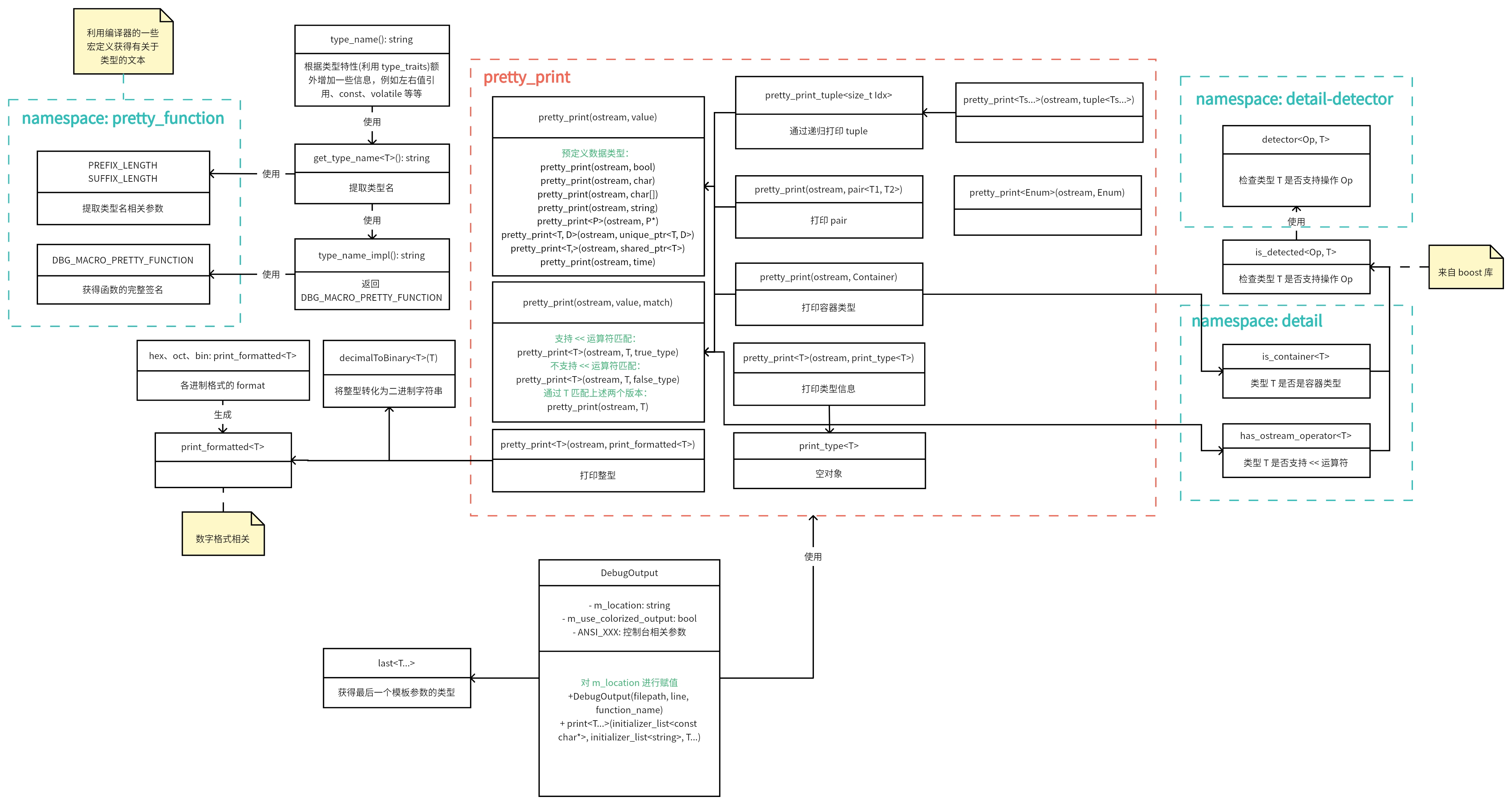
1. 获取类型信息
这部分的功能是获取一个变量详细的类型信息。
#if defined(__clang__)
#define DBG_MACRO_PRETTY_FUNCTION __PRETTY_FUNCTION__
static constexpr size_t PREFIX_LENGTH =
sizeof("const char *dbg::type_name_impl() [T = ") - 1;
static constexpr size_t SUFFIX_LENGTH = sizeof("]") - 1;
#endif
首先我们来看第一段,__PRETTY_FUNCTION__,这实际上是一个编译器的宏,能够获取当前函数的完整签名,在这里被用来获取类型信息。
template <typename T>
const char* type_name_impl() {
return DBG_MACRO_PRETTY_FUNCTION;
}
在该函数中会调用宏 __PRETTY_FUNCTION__,所得到的函数签名字符串就是 const char *dbg::type_name_impl() [T = XXX],会改变的只有类型 T 所对应类型的字符串,所以知道前缀和后缀长度就可以获得类型 T 所对应的字符串信息,由此来获得类型信息。
template <typename T>
struct type_tag {};
template <typename T>
std::string get_type_name(type_tag<T>) {
namespace pf = pretty_function;
std::string type = type_name_impl<T>();
return type.substr(pf::PREFIX_LENGTH,
type.size() - pf::PREFIX_LENGTH - pf::SUFFIX_LENGTH);
}
// ...
inline std::string get_type_name(type_tag<std::string>) {
return "std::string";
}
// ...
这一部分对标准库中的一些类型进行了特化,增加可读性,在标准库中,类型 std::string 得出的类型信息是 std::basic_string<char>,其他类型也有类似的情况,这里对这些标准库的类型信息进行指定。
至于这里为什么用一个空对象
type_tag来进行模板匹配,个人觉得是为了增加可读性,没什么特别的含义,明确告知参数只是个类型的 tag,没什么其他用。
template <typename T> std::string type_name() {
if (std::is_volatile<T>::value) {
if (std::is_pointer<T>::value) {
return type_name<typename std::remove_volatile<T>::type>() +
" volatile";
} else {
return "volatile " +
type_name<typename std::remove_volatile<T>::type>();
}
}
if (std::is_const<T>::value) {
if (std::is_pointer<T>::value) {
return type_name<typename std::remove_const<T>::type>() + " const";
} else {
return "const " + type_name<typename std::remove_const<T>::type>();
}
}
if (std::is_pointer<T>::value) {
return type_name<typename std::remove_pointer<T>::type>() + "*";
}
if (std::is_lvalue_reference<T>::value) {
return type_name<typename std::remove_reference<T>::type>() + "&";
}
if (std::is_rvalue_reference<T>::value) {
return type_name<typename std::remove_reference<T>::type>() + "&&";
}
return get_type_name(type_tag<T>{});
}
这一部分则利用了 type_traits,判断参数的各种特性,例如 volatile、左右值等等,增加一些额外的 debug 信息。
最终在宏 #define DBG_TYPE_NAME(x) dbg::type_name<decltype(x)>() 中使用到,这里的参数 x 会自动推导出类型传入 type_name
源码中定义了类
print_formatted,这部分是关于数字进制的打印问题,属于具体实现,本文主要讲原理部分,这部分就略过了。
这部分最后再讲讲获取 tuple 类型信息的实现,由于 tuple 有不定长的模板参数,这里需要用到特殊的方法。
这里就存在一个关于可变模板参数的一个知识点,通过形式 ((func(arg)), ...); 来获得每一个参数,一个例子如下:
template<typename... T>
void t(T... args){
((cout << args << endl), ...);
}
t(1, 1.5, "123");
// output:
// 1
// 1.5
// 123
在源码中,还使用了一个很少见的初始化列表的用法
template <typename... T>
std::string type_list_to_string() {
std::string result;
auto unused = {(result += type_name<T>() + ", ", 0)..., 0};
static_cast<void>(unused);
if (sizeof...(T) > 0) {
result.pop_back();
result.pop_back();
}
return result;
}
这里 unused 就是个没什么用的东西,实际类型是 initializer_list<int>,这里的用法是 {(func(), var), (func2(), var2)},初始化列表会执行括号里的第一个表达式,然后取第二个值,也就是 var 作为初始化列表的内容。
所以在该部分,unused 只是将所有参数都执行一遍 type_name 并加到 result 中,从而实现 tuple 类型信息的获取。
个人认为这部分属于奇技淫巧了,降低可读性的同时引入了一个不会被使用到的变量,个人觉得不是个好的实现方式。
个人认为更好的实现方式如下,增强可读性的同时也删去了无用变量:
template<typename T>
void add_type(std::string& str){
str += get_type_name<T>() + ", ";
}
template <typename... T> std::string type_list_to_string() {
std::string result;
((add_type<T>(result)), ...);
if (sizeof...(T) > 0) {
result.pop_back();
result.pop_back();
}
return result;
}
2. 打印值
第一部分讲了获取值的类型信息,这部分就是打印值的内容了,在源码中对应 pretty_print 部分,这部分重载函数多达 19 个,有相当复杂的关系,是该库最核心最庞大的部分,本文只列举其中一部分最核心的,需要了解函数模板的匹配规则(具体可参考 微软函数模板匹配文档)。
首先这部分使用了一个叫 is_detected 的 type_traits,这部分在标准库中没有,但在 boost 库中有实现,该库这部分实际上就是来自 boost 库,本文就略过了
如果想要了解其工作原理,可以查看这篇文章:C++ 黑魔法初探:boost 库 is_detected
在 pretty_print 这部分,定义了泛型值信息打印和特化的值信息打印,特化的部分则是标准库内的类型,除了基础类型,还实现了智能指针、容器等等的特化。
这里的泛型值指的是非特化版本的值类型,也就是用户自己定义的类型,标准库中可打印的类型及基础类型都有特化匹配的版本
泛型值的打印则需要该类支持 << 运算符,能够打印到标准输出的类才能够打印,其实现如下:
template <typename T>
inline void pretty_print(std::ostream& stream, const T& value, std::true_type) {
stream << value;
}
template <typename T>
inline void pretty_print(std::ostream&, const T&, std::false_type) {
static_assert(detail::has_ostream_operator<const T&>::value,
"Type does not support the << ostream operator");
}
template <typename T>
inline typename std::enable_if<!detail::is_container<const T&>::value &&
!std::is_enum<T>::value,
bool>::type
pretty_print(std::ostream& stream, const T& value) {
pretty_print(stream, value,
typename detail::has_ostream_operator<const T&>::type{});
return true;
}
第三个重载是一般调用形式,对于参数会进行特化,从而匹配第一或者第二个版本,第一个版本则代表参数 value 包含 << 运算符,可以支持标准输出,而第二个版本则代表不支持,会报错。
至于返回类型中的 enable_if,则保证了第三个版本只会匹配非容器和非枚举的类型,因为容器类型和枚举类型有另外的匹配函数,这里如果不做限制,则会产生歧义。
常规值的打印均略过,这里讲一下 tuple 的打印
template <size_t Idx>
struct pretty_print_tuple {
template <typename... Ts>
static void print(std::ostream& stream, const std::tuple<Ts...>& tuple) {
pretty_print_tuple<Idx - 1>::print(stream, tuple);
stream << ", ";
pretty_print(stream, std::get<Idx>(tuple));
}
};
template <>
struct pretty_print_tuple<0> {
template <typename... Ts>
static void print(std::ostream& stream, const std::tuple<Ts...>& tuple) {
pretty_print(stream, std::get<0>(tuple));
}
};
template <typename... Ts>
inline bool pretty_print(std::ostream& stream, const std::tuple<Ts...>& value) {
stream << "{";
pretty_print_tuple<sizeof...(Ts) - 1>::print(stream, value);
stream << "}";
return true;
}
template <>
inline bool pretty_print(std::ostream& stream, const std::tuple<>&) {
stream << "{}";
return true;
}
这里用到了对于可变模板参数的常用技法,在标准库中使用频率也很高,就是递归可变模板参数,虽然这里递归的是数字,而不是参数,但是原理类似。
正常调用时,首先会调用第一个泛型的类,此时模板参数有多个,接着递归调用自身,直到 Idx 为 0 时,调用第二个特化的类,此时就会打印第 0 个元素,接着递归开始返回,打印第 1 个、第 2 个…直到结束。
打印容器类:库对容器的定义是包含 begin(), end(), size() 成员的类即是容器
template <typename Container>
inline typename std::enable_if<detail::is_container<const Container&>::value,
bool>::type
pretty_print(std::ostream& stream, const Container& value) {
stream << "{";
const size_t size = detail::size(value);
const size_t n = std::min(size_t{10}, size);
size_t i = 0;
using std::begin;
using std::end;
for (auto it = begin(value); it != end(value) && i < n; ++it, ++i) {
pretty_print(stream, *it);
if (i != n - 1) {
stream << ", ";
}
}
if (size > n) {
stream << ", ...";
stream << " size:" << size;
}
stream << "}";
return true;
}
这里同样在返回类型进行匹配,是一种偏特化匹配的技巧(SFINAE),使用 enable_if 只有满足时才会匹配该版本,不满足也不会报错,会去匹配其他版本。
所以该函数首先检查该类型是否是容器,也就是是否支持 begin, end, size 操作,这里调用标准库的 std::begin, std::end,保证了其值是个迭代器,如果支持则在函数内可以放心调用
打印类型信息:A [sizeof: 1 byte, trivial: yes, standard layout: yes]
template <typename T>
struct print_type {};
template <typename T>
print_type<T> type() {
return print_type<T>{};
}
template <typename T>
inline bool pretty_print(std::ostream& stream, const print_type<T>&) {
stream << type_name<T>();
stream << " [sizeof: " << sizeof(T) << " byte, ";
stream << "trivial: ";
if (std::is_trivial<T>::value) {
stream << "yes";
} else {
stream << "no";
}
stream << ", standard layout: ";
if (std::is_standard_layout<T>::value) {
stream << "yes";
} else {
stream << "no";
}
stream << "]";
return false;
}
// 用法:
dbg(dbg::type<A>());
这里使用了一个空类型进行显式的匹配,打印一个类型的简单信息。
3. DebugOutput
声明一个类对上述的功能进行组合和调用,以打印出完整的 debug 信息。
对类简化后的代码:
class DebugOutput {
public:
using expr_t = const char*;
DebugOutput(filepath, line, function_name){
// 初始化代码位置信息...
}
// last_t 返回最后一个变量,其实现原理和后续讲解的递归类似
// 本文就不赘述了,最终是为了支持例如 return dbg(var); 的
// 语句实现,可以无感嵌入到代码中,无需额外写出 debug 的语句
template <typename... T>
auto print(std::initializer_list<expr_t> exprs,
std::initializer_list<std::string> types, T&&... values)
-> last_t<T...> {
if (exprs.size() != sizeof...(values)) {
// 错误...
}
return print_impl(exprs.begin(), types.begin(),
std::forward<T>(values)...);
}
private:
template <typename T>
T&& print_impl(const expr_t* expr, const std::string* type, T&& value) {
const T& ref = value;
std::stringstream stream_value;
const bool print_expr_and_type = pretty_print(stream_value, ref);
std::stringstream output;
output << m_location;
if (print_expr_and_type) {
// 打印表达式 [变量X = ]
output << *expr << " = ";
}
// 打印变量值
output << stream_value.str();
if (print_expr_and_type) {
// 打印表达式 [(变量类型)]
output << " (" << *type << ")";
}
output << std::endl;
std::cerr << output.str();
return std::forward<T>(value);
}
// 如果输入值有多个,递归调用
template <typename T, typename... U>
auto print_impl(const expr_t* exprs_itr, const std::string* types_itr, T&& value,
U&&... rest) -> last_t<T, U...> {
print_impl(exprs_itr, types_itr, std::forward<T>(value));
return print_impl(exprs_itr + 1, types_itr + 1, std::forward<U>(rest)...);
}
std::string m_location;
// 控制台颜色相关...
};
对于一个类,我们首先得清楚他的输入是什么,函数 print() 接受三个参数,第一个是表达式,也就是使用 dbg(expression) 时,获取输入的表达式是什么(该表达式会被转化为字符串,后续宏中会有讲解),第二个参数是类型,也就是表达式所对应的类型是什么,第三个则是值,也就是表达式的值是什么。
所以为了支持如:[../Cpp/main.cpp:22 (main)] i = 1 (int) 的打印信息,我们得输入变量名,变量类型及其值,其中的递归调用,则是为了支持一条语句可以输出多个信息,例如:dbg(var1, var2);
所以实际上该类没有什么特别复杂的工作,仅仅只是将传入的信息打印出来而已,也就其递归调用可以讲讲。
首先调用的是 print() 函数,其工作委托给 print_impl(),注意传入的值是迭代器,所以 +1 操作是指向下一个字符串。
简化后的迭代关系:
template <typename T>
void print_impl(...) {
//...
}
// 如果输入值有多个,递归调用
template <typename T, typename... U>
void print_impl(..., T&& value, U&&... rest) {
// 使用 value...
print_impl(exprs_itr + 1, types_itr + 1, std::forward<U>(rest)...);
}
注意在 print_impl<T, ...U> 中,T 会被使用,而 U... 会被递归地传递下去,到下一个 print_impl<T, ...U> 时,上一轮的 U... 会被拆成 <T, ...U>,也就是每一轮迭代,可变模板参数就会少一个,最终只剩一个的时候,匹配 print_impl<T>,从而完成迭代。
4. 宏
到这一步,所有需要的拼图碎片都集齐了,最后就是使用宏将上述的碎片拼接起来。
宏这一部分仍然有复杂的嵌套关系,需要一步步捋清楚。
#define DBG_IDENTITY(x) x
#define DBG_CALL(fn, args) DBG_IDENTITY(fn args)
#define DBG_CAT_IMPL(_1, _2) _1##_2
#define DBG_CAT(_1, _2) DBG_CAT_IMPL(_1, _2)
#define DBG_16TH_IMPL(_1, _2, _3, _4, _5, _6, _7, _8, _9, _10, _11, _12, _13, \
_14, _15, _16, ...) \
_16
#define DBG_16TH(args) DBG_CALL(DBG_16TH_IMPL, args)
#define DBG_NARG(...) \
DBG_16TH((__VA_ARGS__, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0))
// DBG_VARIADIC_CALL(fn, data, e1, e2, ...) => fn_N(data, (e1, e2, ...))
#define DBG_VARIADIC_CALL(fn, data, ...) \
DBG_CAT(fn##_, DBG_NARG(__VA_ARGS__))(data, (__VA_ARGS__))
// (e1, e2, e3, ...) => e1
#define DBG_HEAD_IMPL(_1, ...) _1
#define DBG_HEAD(args) DBG_CALL(DBG_HEAD_IMPL, args)
// (e1, e2, e3, ...) => (e2, e3, ...)
#define DBG_TAIL_IMPL(_1, ...) (__VA_ARGS__)
#define DBG_TAIL(args) DBG_CALL(DBG_TAIL_IMPL, args)
#define DBG_MAP_1(fn, args) DBG_CALL(fn, args)
#define DBG_MAP_2(fn, args) fn(DBG_HEAD(args)), DBG_MAP_1(fn, DBG_TAIL(args))
#define DBG_MAP_3(fn, args) fn(DBG_HEAD(args)), DBG_MAP_2(fn, DBG_TAIL(args))
// ...
#define DBG_MAP_16(fn, args) fn(DBG_HEAD(args)), DBG_MAP_15(fn, DBG_TAIL(args))
// DBG_MAP(fn, e1, e2, e3, ...) => fn(e1), fn(e2), fn(e3), ...
#define DBG_MAP(fn, ...) DBG_VARIADIC_CALL(DBG_MAP, fn, __VA_ARGS__)
#define DBG_STRINGIFY_IMPL(x) #x
#define DBG_STRINGIFY(x) DBG_STRINGIFY_IMPL(x)
#define DBG_TYPE_NAME(x) dbg::type_name<decltype(x)>()
#define dbg(...) \
dbg::DebugOutput(__FILE__, __LINE__, __func__) \
.print({DBG_MAP(DBG_STRINGIFY, __VA_ARGS__)}, \
{DBG_MAP(DBG_TYPE_NAME, __VA_ARGS__)}, __VA_ARGS__)
我们从最上层调用 dbg(...) 开始,... 是宏的可变参数,其使用为 __VA_ARGS__。可以看到,在该宏中,我们用 __FILE__, __LINE__, __func__ 作为 DebugOutput 的初始化参数,给了它关于代码位置的信息,随后传入了两个初始化列表,{DBG_MAP(DBG_STRINGIFY, __VA_ARGS__)} 和 {DBG_MAP(DBG_TYPE_NAME, __VA_ARGS__)},最后再传入了本来的变量。
这里遇到的第一个宏展开是 DBG_MAP,他做了什么事呢,源码注释中有写道:// DBG_MAP(fn, e1, e2, e3, ...) => fn(e1), fn(e2), fn(e3), ...,那么就看其如何实现的。
由于宏的展开链非常长,首先需要对各个模块进行拆解,方便理解:
第一个是拼接宏 DBG_CAT(_1, _2)
// ## 在宏中的作用就是实现 _1 和 _2 的连接
// 例如 DBG_CAT_IMPL(func, (var)) -> 展开为 func(var)
#define DBG_CAT_IMPL(_1, _2) _1##_2
#define DBG_CAT(_1, _2) DBG_CAT_IMPL(_1, _2)
第二个是计算数量 DBG_NARG(...),也就是可变参数中有多少个元素
// 这里 16 的含义是 dbg-macro 最多支持一条语句打印 15 个表达式的信息
// 其中一个会被 DBG_16TH_IMPL 占用,后续有讲解
#define DBG_NARG(...) \
DBG_16TH((__VA_ARGS__, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0))
// DBG_16TH(args) 该宏会展开为第 16 个参数,结合上述传入的 15-0 的数字
// 如果 __VA_ARGS__ 有一个参数,则展开为 1,如果有 10 个参数则展开为 10
#define DBG_16TH_IMPL(_1, _2, _3, _4, _5, _6, _7, _8, _9, _10, _11, _12, _13, \
_14, _15, _16, ...) \
_16
// 这里 DBG_16TH_IMPL 占用了一个参数,所以一条语句最多打印 15 个表达式
#define DBG_16TH(args) DBG_CALL(DBG_16TH_IMPL, args)
第三个是获取可变参数的头和去头后的序列:DBG_HEAD(args),DBG_TAIL(args)
这里传入的参数 args = (__VA_ARGS__),注意,带有括号,所以可以看作是一个参数 args,然后调用 DBG_CALL(fn, args) -> fn(args)。这里实际上只会有一个参数,因为其传入的参数 args 是由 DBG_HEAD_IMPL(args) 获得的,只有一个参数,DBG_TAIL(args) 也类似
// (e1, e2, e3, ...) => e1
#define DBG_HEAD_IMPL(_1, ...) _1
#define DBG_HEAD(args) DBG_CALL(DBG_HEAD_IMPL, args)
// (e1, e2, e3, ...) => (e2, e3, ...)
#define DBG_TAIL_IMPL(_1, ...) (__VA_ARGS__)
#define DBG_TAIL(args) DBG_CALL(DBG_TAIL_IMPL, args)
第四个是定长调用链:DBG_MAP_X(fn, args),args 是一个由括号括起来的可变参数 (__VA_ARGS__),这里看作是一个参数。
// 对于一个可变参数列表,会逐一展开
// DBG_MAP(fn, e1, e2, e3, ...) => fn(e1), fn(e2), fn(e3), ...
// 展开过程:
// DBG_MAP_3(fn, args) fn(DBG_HEAD(args)), DBG_MAP_2(fn, DBG_TAIL(args))
// -> fn(first_ele), DBG_MAP_2(fn, DBG_TAIL(args))
// -> fn(first_ele), fn(second_ele), DBG_MAP_1(fn, DBG_TAIL(args))
// -> fn(first_ele), fn(second_ele), fn(last_ele)
#define DBG_MAP_1(fn, args) DBG_CALL(fn, args)
#define DBG_MAP_2(fn, args) fn(DBG_HEAD(args)), DBG_MAP_1(fn, DBG_TAIL(args))
#define DBG_MAP_3(fn, args) fn(DBG_HEAD(args)), DBG_MAP_2(fn, DBG_TAIL(args))
// 省略...
#define DBG_MAP_16(fn, args) fn(DBG_HEAD(args)), DBG_MAP_15(fn, DBG_TAIL(args))
我们再回到最上层的调用:
#define DBG_MAP(fn, ...) DBG_VARIADIC_CALL(DBG_MAP, fn, __VA_ARGS__)
#define DBG_VARIADIC_CALL(fn, data, ...) \
DBG_CAT(fn##_, DBG_NARG(__VA_ARGS__))(data, (__VA_ARGS__))
// 以 __VA_ARGS__ = var1, var2 为例,调用 DBG_MAP 时,会展开为
// {DBG_MAP(DBG_STRINGIFY, __VA_ARGS__)}
// ->
// {DBG_MAP(DBG_STRINGIFY, var1, var2)}
// ->
// {DBG_VARIADIC_CALL(DBG_MAP, DBG_STRINGIFY, var1, var2)}
// ->
// {DBG_CAT(DBG_MAP_, DBG_STRINGIFY, (var1, var2))}
// ->
// {DBG_CAT(DBG_MAP_, DBG_NARG(var1, var2))(DBG_STRINGIFY, (var1, var2))}
// ->
// {DBG_MAP_2(DBG_STRINGIFY, (var1, var2))}
// ->
// {DBG_STRINGIFY(var1), DBG_STRINGIFY(var2)}
// ->
// {"var1", "var2"}
// 在宏中 # 就是将变量 x 转化为字符串形式
#define DBG_STRINGIFY_IMPL(x) #x
#define DBG_STRINGIFY(x) DBG_STRINGIFY_IMPL(x)
通过以上调用链,就获得了变量的字符串,也就完成了 print() 函数所需要的第一个初始化列表,表达式的字符串。
第二个初始化列表也类似,获得变量的类型,只不过其调用函数从 DBG_STRINGIFY(x) 变成了 DBG_TYPE_NAME(x),该宏展开为 dbg::type_name<decltype(x)>()
所以有以下展开链:
// 以 __VA_ARGS__ = var1, var2 为例,调用 DBG_MAP 时,会展开为
// {DBG_MAP(DBG_TYPE_NAME, __VA_ARGS__)}
// 与上述类似,略...
// {DBG_TYPE_NAME(var1), DBG_TYPE_NAME(var2)}
// ->
// {"int", "double"}
最后一个参数 __VA_ARGS__ 就是把参数本身传入而已。
完结
dbg-macro 虽然只有短短 900+ 行,但是其中的知识密度一点都不小,涉及模板元编程和复杂的宏展开,本文只是挑取其中最核心的部分进行讲解,如果要完全理解该库的运行,还得回到源码,此外,本文仅进行了 C++11 的内容进行了分析,该库还支持 C++17 新引入的一些类型,本文就不做讲解了(其实对新标准还没有深入了解)